
前言
此篇是旧博客迁移的文章之一,但在今天(2022-8-10)对内容进行了大量的补充与修正。为何今天才修改内容?主要是因为最近的精力在学习 python 爬虫,在准备爬虫文章的更新,因此搁置了 V8 引擎。平心而论,V8 引擎系列文章会是我真正意义上的”专栏”,一切源于兴趣使然。当然,Chrome 成为当今浏览器巨头的原因,很大一部分在于 V8 引擎,因此我会尝试去阅读 V8 源码,尽管它有一部分源码由 C++组成,但仍有大部分源码使用了 JavaScript,可能不会将源码阅读完(实际上对我来说也不可能),但这能够进一步去了解 V8,算是我对它的 respect…
文章的时间记为 2022-4-9,实际上我也是从这一天开始了解 V8 引擎,就让时间回溯到那一天开始…
为什么需要 JavaScript 引擎呢?
由于 JavaScript 是高级编程语言,而高级编程语言都是需要转成最终的机器指令来执行的。事实上,我们编写的 JavaScript 代码无论交给浏览器或者 Node 来执行,最后都是需要被CPU执行的。但只有机器语言才能被 CPU 执行, 因此JavaScript 引擎帮助我们将 JavaScript 代码编译成 CPU 指令来执行。
常见的 JavaScript 引擎有哪些?
- SpiderMonkey: 第一款 JavaScript 引擎,由 JavaScript 之父开发
- JavaScriptCore: WebKit 中的 JavaScript 引擎,小程序也在使用该引擎
- V8: Chrome 浏览器的 JavaScript 引擎
浏览器内核和 JavaScript 引擎的关系
以 WebKit 为例子,WebKit 事实上由两部分组成:
- WebCore:负责HTML 解析、布局、渲染等相关工作
- JavaScriptCore:解析、执行 JavaScript 代码
什么是 d8?
d8 是 V8 引擎的一个调试工具,通过 d8 的一些指令,我们可以查看 V8 引擎在执行 JavaScript 代码过程中的各种中间数据,比如作用域、AST、bytecode(字节码)、优化的二进制代码、垃圾回收的状态等
如何在 Windows 上安装 d8?
一般来说,网上没有直接获取 d8 的途径,而是通过编译 V8 的源码来生成 d8。
如何通过编译 V8 的源码构建 d8?
这里我简单概括下,分为三步:下载 V8 源码 -> 生成工程文件 -> 通过相关工具的指令编译 V8 的工程并生成 d8
这里,我在网上找到了其他大佬编译好的 d8:
- Windows 系统 64 位:https://storage.googleapis.com/chromium-v8/official/canary/v8-win64-dbg-8.4.109.zip
- Mac 系统:https://storage.googleapis.com/chromium-v8/official/canary/v8-mac64-dbg-8.4.109.zip
介于我使用的是 Windows 系统,下面我将介绍如何在 Windows 系统下安装 d8:
- 通过上方的链接,下载压缩包,解压压缩包到任何地方都行
- 打开解压出的文件,会发现一个
d8.exe文件 - 此时,将
d8.exe所在的文件路径 copy 一下 - 打开高级系统设置,点击环境变量
- 在系统变量中的 path 里添加刚刚 copy 的文件路径
测试是否安装成功:
- 添加成功后,可以检测一下 d8 是否可以使用,在电脑的任何地方,按住 shift 键+鼠标右键,选择启动
PowerShell窗口 - 输入
d8 --help命令,若出现很多行即表示可以使用 d8 了

V8 引擎的原理
V8 引擎是由 C++编写的高性能JavaScript和 WebAssembly 引擎,它能实现 ECMAScript 和 WebAssembly,也能独立运行并嵌入到任何 C++应用程序中。
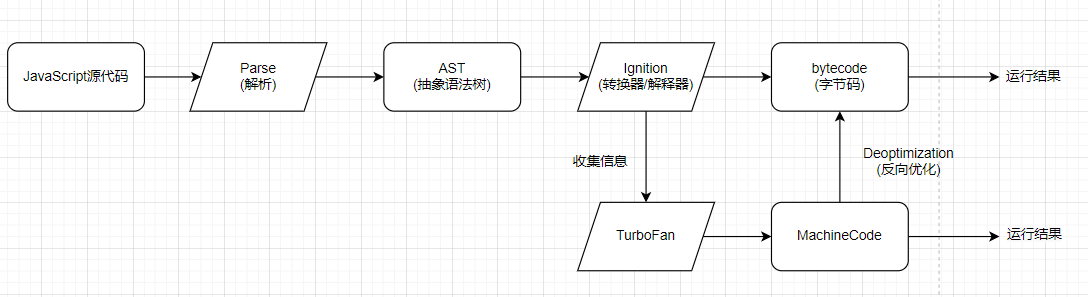
(V8 引擎-过程图)
优化策略
- 函数只声明并且未被调用, 则不会被解析成 AST
- 函数若只被调用一次, bytecode 则直接被 Ignition 解释执行
- 函数若被多次调用, Ignition 会将该函数标记为 hot 函数, 若多次调用且参数都为相同类型, 则会被编译成 MachineCode; 若多次调用并且传入不同类型的参数, 则会被反向优化成 bytecode
过程分段解析
过程一
JavaScript 源代码 -> Parse(解析) -> AST(抽象语法树)
const name = 'licodeao';
// Parse(解析) = 词法分析 + 语法分析
1.词法分析:
词法分析类似切割,将一段代码分成几部分
JS代码经过Parse中的词法分析后
↓
生成一个tokens数组,并且数组里面是一个个对象(类似JSON),tokens = []
↓
词法分析从左到右依次分析代码
↓
遇见const时,会将它解析为关键字类型,并往tokens数组中添加
tokens: [{ type: 'keyword', value: 'const' }]
↓
随后遇见name,将它解析为标识符类型,往tokens数组中添加
tokens: [
{ type: 'keyword', value: 'const'},
{ type: 'identifier', value: 'name' }]
↓
再往后遇见'licodeao',将它解析为字面量类型,往tokens数组中添加
此时tokens: [
{ type: 'keyword', value: 'const'},
{ type: 'identifier', value: 'name' },
{ type: 'literal', value: 'licodeao'}]
2.语法分析:
得益于词法分析的类切割效果,tokens数组中存储的是一个个对象,那么接下来就会对这些对象进行语法分析
↓
进而生成一个AST(抽象语法树)过程二
AST(抽象语法树) -> Ignition(转换器/解释器) -> bytecode(字节码)
// 过程概述
语法分析生成了AST抽象语法树之后,再通过ignition转换器,将抽象语法树中的各个语法,转换为对应的字节码
此时V8引擎就会将字节码转换为不同平台上的CPU指令
// 那么,如何执行这些CPU指令呢?
在上一步中,字节码会先被转为汇编代码,通过汇编代码去执行CPU指令,进而得到最开始的JS代码的运行结果
字节码 -> 汇编代码 -> 通过汇编代码执行CPU指令 -> 运行结果
因此,实际上在字节码被转换为运行结果之间,需要被转换为汇编代码AST(抽象语法树) -> Ignition(转换器/解释器) -> TurboFan(编译器)
// 过程概述
在JS代码中,可能会有部分函数被执行多次
↓
那么此时ignition会将该函数标记为hot(热函数),并交给TurboFan进行转换
↓
转换为对应的MachineCode(优化的机器码)
↓
那么当下次再执行该函数时,即可不通过转换,就能直接执行机器指令,得到运行结果,提高了性能
--------------------------------------------------------------------------------------------------------
但会出现一个问题,例如一个sum求和函数
function sum(num1, num2) {
return num1 + num2;
}
sum(20,10) -> 第一次调用sum函数,参数为Number类型
sum(30,20) -> 第二次调用sum函数,参数为Number类型,此时被ignition标记为hot(热函数)
sum('aaa','bbb') -> 第三次调用sum函数,参数为String类型
第二次调用sum函数时,被ignition标记为hot(热函数),交给TurboFan(编译器)转换为对应的MachineCode(优化机器码)
// 第三次调用sum函数时,会不用通过TurboFan转换,直接执行机器指令吗?
显然不会!
此时,问题出现了,前两次传的是Number类型,并返回的是一个Number类型
而第三次调用sum函数时,传的是String类型,那么此时返回的是字符串拼接的结果,显然与之前转换成的机器码相悖了
// 那么,如何解决这种传递不同类型参数的问题呢?
V8引擎提供了一个Deoptimization(反向优化)的解决方案,这也是相比较于5.9版本之前的V8引擎所增添的一点
当遇到了不同类型参数的问题时,V8引擎就会将原来的MachineCode(优化机器码)通过Deoptimization(反向优化)转换为bytecode(字节码),因为之前的MachineCode(优化机器码)不能正确地处理运算!
↓
bytecode(字节码)转换为汇编代码
↓
通过汇编代码去执行CPU指令
↓
运行结果
解决了这问题,必然得浪费一点性能(因为执行了反向优化的过程)
// 假如用TypeScript重写sum函数,是否能提高一点性能呢?
function sum(num1:number, num2:number) {
return num1 + num2;
}
答案在某种意义上来说,是肯定的,因为TypeScript的强类型使得sum函数只能传递同样类型的参数,这就符合上面说的第一种情况,即没有出现传递不同类型参数的问题。V8 引擎的架构
-
Parse 模块:
Parse 模块会将 JavaScript 代码转换成抽象语法树,帮助 Ignition 解释器认识 JavaScript 代码
如果函数没有被调用,则不会被转换为抽象语法树
-
Ignition 解释器:
Ignition 解释器会将抽象语法树转换为 bytecode 字节码
同时会收集 TurboFan 优化所需要的信息(比如函数参数的类型信息)
如果函数只调用一次,Ignition 会直接执行解释 bytecode 字节码
-
TurboFan 编译器:
如果一个函数被多次调用,那么就会被 Ignition 标记为 hot 热函数,随后被 TurboFan 转换成优化的机器码,提高性能
当出现类型发生变化时,机器码会被还原成 bytecode, 因为之前的优化机器码并不能正确的处理运算,所以就会被逆向的转化成字节码,降低性能
V8 执行的细节
Parse(解析)阶段

(V8 引擎的解析图-官方)
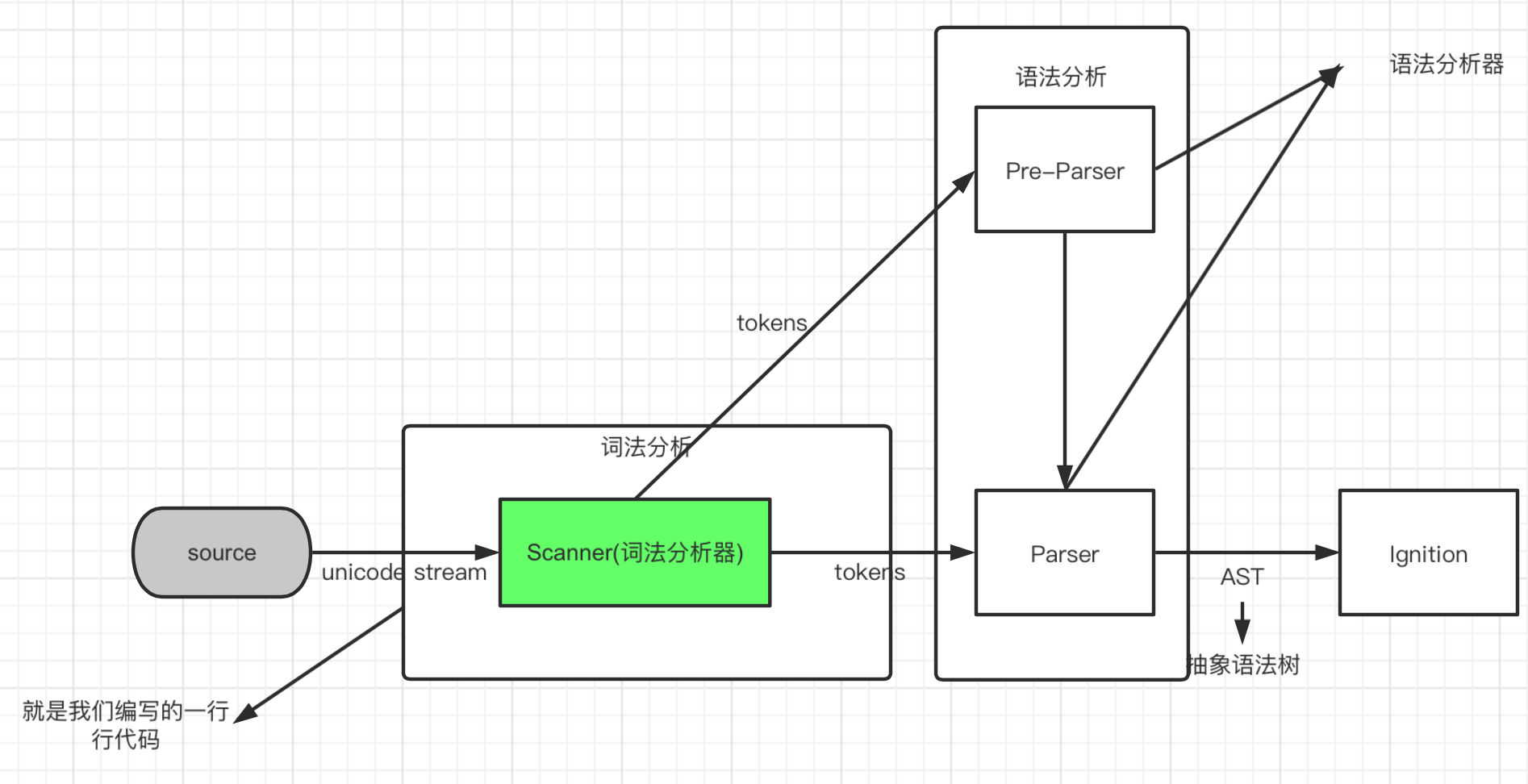
// 过程概况
1.首先Blink内核会将源码交给V8引擎,Stream获取到源码并且进行编码转换
↓
2.Scanner(词法分析器)会进行词法分析(lexical analysis),将代码转换成tokens数组
↓
3.通过语法分析,将tokens转换成AST树,此时经过Parser和PreParser(预解析):
// Parser就是直接将tokens转换成AST树架构
// PreParser是预解析,为什么需要预解析呢?
1.并不是所有的JavaScript代码,在一开始时就会被执行。那么对所有的JavaScript代码进行解析,必然会影响网页的运行效率
2.因此V8引擎就实现了Lazy Parsing(延迟解析)的方案,它的作用是将不必要的函数进行预解析,也就是只解析暂时需要的内容,而对函数的全量解析是在函数被调用时才会进行。
// example
function foo() {
function sum() {
var i = 0;
console.log(i)
}
}
foo()
就如上方的代码,foo函数被调用了,执行该函数。
↓
V8引擎会查看foo函数内部的成员,于是发现了sum函数,但sum函数并没有被调用,因此V8引擎知道了foo函数内部有个sum函数,但不会去管sum函数,先晾在一旁。也就是说:在foo函数内部定义了一个sum函数,那么sum函数就会进行预解析(大白话就是看到了不管它,因为sum函数没有被调用)
↓
4.生成AST树后,会被Ignition转换器转成字节码bytecode,字节码再转成汇编代码,通过汇编代码去运行不同平台上的CPU指令得到运行结果未完待续…