
一、 robots.txt协议
规定了网站中哪些数据可以被爬虫爬取,哪些数据不可爬(非要爬也行,大不了进 🍊)

(b 站 robots.txt协议)
二、Web 请求过程
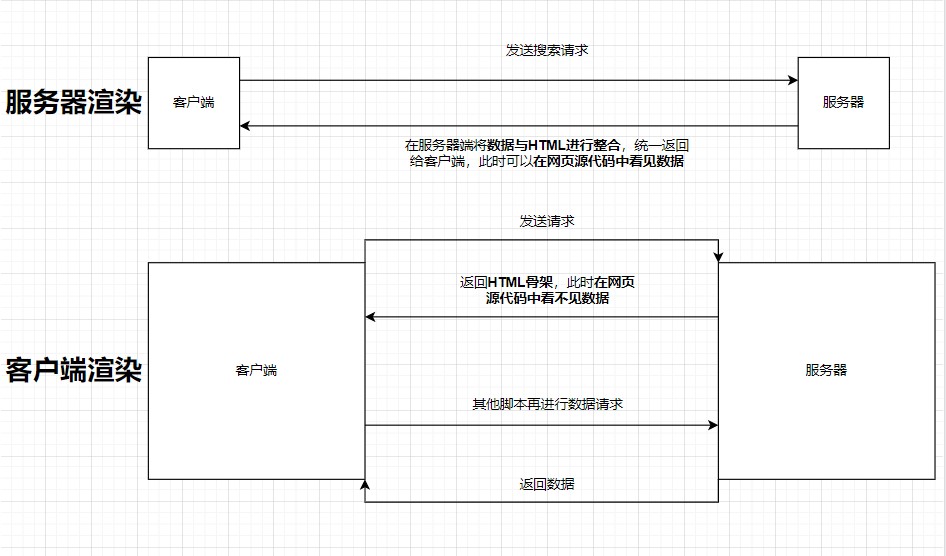
服务器渲染与客户端渲染的区别
| 服务器渲染 | 服务器将数据与 HTML 整合,统一返回给客户端,源代码中可看见数据(一次请求) |
|---|---|
| 客户端渲染 | 服务器返回 HTML 骨架,源代码中看不见数据(多次请求返回数据) |
三、请求头与响应头
- 请求头中常见的一些重要内容
User-Agent:请求载体的身份标识Referer:防盗链(请求从哪个页面来的?反爬会用到)cookie:本地字符串数据信息(用户登录信息,反爬的 token)
- 响应头中常见的一些重要内容
cookie:本地字符串数据信息(用户登录信息,反爬的 token)- 各种莫名其妙的字符串:防止攻击和反爬
四、requests
requests 相对于urllib简化了许多步骤,使用起来更为方便
import requests
url = 'https://www.xxx.com'
# get请求对应的参数是params,post请求对应的参数是data
params = {
"type": "24",
"id": "100:90",
"start": 0,
"limit": 20
}
response = requests.get(url = url, params = params)
print(response.text) -> 若此时无数据,则表明对方做了反爬
# 注意最后记得关闭请求,防止访问过多
response.close()五、数据解析与提取
多数情况下,并不需要整个网页的内容,只需要一小部分,因此需要进行数据提取。
-
re解析正则表达式解析
# 以下都为元字符 . 匹配除换行符以外的任意字符 \w 匹配字母、数字、下划线 \s 匹配任意的空白字符 \d 匹配数字 \n 匹配一个换行符 \t 匹配一个制表符 ^ 匹配字符串的开始 $ 匹配字符串的结束 \W 匹配非字母或数字或下划线 \D 匹配非数字 \S 匹配非空白符 a|b 匹配字符a或字符b () 匹配括号内的表达式 [...] 匹配字符组中的字符 [^...] 匹配除了字符组中字符的所有字符 # 以下都为量词 * 重复0次或更多次 + 重复一次或更多次 ? 重复0次或1次 {n} 重复n次 {n,} 重复n次或更多次 {n,m} 重复n到m次 # 贪婪匹配与惰性匹配 .* 贪婪匹配 .*? 惰性匹配 # re模块 import re 1. findall() -> 匹配字符串中所有符合正则的内容 lst = re.findall(r"\d+","电话号码是10086") print(lst) -> ['10086'] 2. finditer() -> 匹配字符串中所有的内容 ite = re.finditer(r"\d+","电话号码是10086") print(ite) -> ['10086'] <callback_iterator object at ......>(返回一个迭代器) for i in ite: print(i) -> <re.Match object; span=(x,y), match='10086'> print(i.group()) -> 10086, 从迭代器中拿到内容需要使用group() 3. search() -> 全文检索, 找到一个结果立即返回, 拿到内容需要使用group() 4. match() -> 从头开始匹配 # 预加载正则表达式 obj = re.compile(r"\d+") ret = obj.finditer("电话号码是10086") for i in ret: print(i.group()) -> 10086 obj = re.compile(r"<div class='.*?'>.*?</div>", re.S) -> re.S:让.能匹配换行符 # 取class的值 先括起来,前面再加?P并起别名,最后在group中获取别名即可 # (?P<别名>正则) -> 可以单独从正则匹配的内容中进一步提取内容 obj = re.compile(r"<div class='(?P<className>.*?)'>.*?</div>", re.S) ret = obj.finditer("...") for i in ret: print(i.group('className')) -> 获取class值 -
bs4解析from bs4 import BeautifulSoup import requests url = 'https://www.xxx.com' response = requests.get(url) 1. 将source code交给BeautifulSoup,并生成bs4对象 page = BeautifulSoup(response, "html.parser") # "html.parser"指定HTML解析器 2. 从bs对象中查找数据 # find(标签名,属性=值) # find_all(标签名,属性=值) tables = page.find("table", class_ = "hq_table") # class_是bs4为了避免报错,因为class是python的关键字 等价于 tables = page.find("table", attr={"class": "hq_table"}) # 此方法也可以避免class报错 print(tables) -
xpath解析xpath 是在 XML 文档中搜索内容的一门语言
''' 1. 将要解析的html内容构造出etree对象 2. 使用etree对象的xpath()方法配合xpath表达式来完成对数据的提取 ''' # example from lxml import etree xml = ''' <book> <id>1</id> <name>野花遍地香</name> <price>1.23<price> <nick>臭豆腐</nick> <author> <nick id="10086">周大强</nick> <nick id="10010">周芷若</nick> <nick class="joy">周杰伦</nick> <nick class="jolin">蔡依林</nick> <div> <nick>哈哈</nick> </div> </author> <partner> <nick id="ppc">碰碰车</nick> <nick id="ppbc">频频爆出</nick> </partner> </book> ''' tree = etree.XML(xml) result = tree.xpath("/book") # / 表示层级关系,第一个/是根节点 result2 = tree.xpath("/book/name/text()") result3 = tree.xpath("/book/author//nick/text()") # // 表示后代 result4 = tree.xpath("./a/@href") # ./ -> 相对查找,@ -> 获取属性值 print(result) -> [<Element book at 0x2078373fec0>] print(result2) -> ['野花遍地香'] # text()获取文本内容 print(result3) -> ['周大强', '周芷若', '周杰伦', '蔡依林', '哈哈']