
requests 进阶
一、使用 cookie 模拟登录
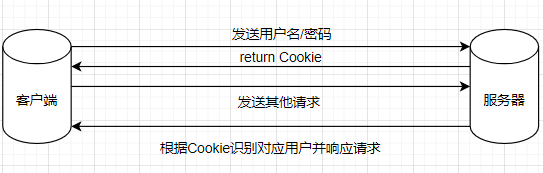
# 登录 -> 得到一个Cookie -> 带着Cookie去请求书架上的url -> 得到书架上的内容 (过程是连续的)
# 这个过程可以使用session进行请求,在这个过程中Cookie并不会丢失
# 创建会话
import requests
url = 'https://xxx.com/ck/user/login'
session = requests.session()
data = {
"loginName": "xxxxxxxxxxxxx",
"password": "xxxxxxxxxxxxx"
}
res = requests.post(url, data=data)
print(res.cookies)
↓
<RequestsCookieJar[<Cookie accessToken=avatarUrl%3Dhttps%253A%252F%252Fcdn.static.17k.com%252Fuser%252Favatar%252F06%252F06%252F06%252F97840606.jpg-88x88%253Fv%253D1660491812000%26id%3D97840606%26nickname%3D%25E4%25B9%25A6%25E5%258F%258B6zCy66999%26e%3D1676044527%26s%3Db4519e3246aeb8b1 for .17k.com/>, <Cookie c_channel=0 for .17k.com/>, <Cookie c_csc=web for .17k.com/>, <Cookie uuid=35633E16-B5B2-170D-9606-6FA83C14B800 for .17k.com/>]>
resp = session.get('https://...com/ck/author/shelf?page=1&appKey=2406394919')
print(resp.text)
# 法二:可以正常地使用requests进行登录,但需要在headers中添加cookie字段(实际上,session也是这么做的,因此两种方法等价)
resp2 = requests.get('https://...com/ck/author/shelf?page=1&appKey=2406394919', headers = {
"Cookie": "..."
})
print(resp2.text)二、防盗链处理
# 以梨视频为例
'''
首先,查看页面源代码发现页面中并不包含video标签,因此可断定视频是经过二次请求获取的。
通过查看Chrome Fetch/XHR可发现请求视频链接,展开json
首页视频地址:https://www.pearvideo.com/video_1731815
元素中video标签包含的src:https://video.pearvideo.com/mp4/adshort/20210610/cont-1731815-15692888_adpkg-ad_hd.mp4
二次请求url:https://www.pearvideo.com/videoStatus.jsp?contId=1731815&mrd=0.011130757000714198
二次请求json返回的srcUrl:https://video.pearvideo.com/mp4/adshort/20210610/1660531619714-15692888_adpkg-ad_hd.mp4
二次请求json返回的systemTime: "1660531619714"
二次请求json所带参数:contId=1731815&mrd=0.5023500046197205
经过测试,发现json返回的视频链接并不存在,而video标签中的视频链接是可以播放的。
对比两个链接,可以发现有不同的地方:cont-1731815 与 1660531619714
那么是否可以将srcUrl中的1660531619714替换成cont-1731815即可
综上所述,真正的视频链接是由contId决定的
于是大致思路:
1. 从首页视频地址:https://www.pearvideo.com/video_1731815分离出contId:1731815
2. 从二次请求返回的json中拿到srcUrl:https://video.pearvideo.com/mp4/adshort/20210610/1660531619714-15692888_adpkg-ad_hd.mp4
3. 将contId替换到srcUrl中即可
'''
import requests
url = 'https://www.pearvideo.com/video_1731815'
contId = url.split('_')[1]
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36',
'''
防盗链:溯源,当前本次请求的上一级是谁,是一种链级关系
例如上面例子中二次请求url的上一级为https://www.pearvideo.com/video_1731815
也就是说只有访问了https://www.pearvideo.com/video_1731815才可以访问二次请求url
'''
"Referer": url
}
vedioStatusUrl = f"https://www.pearvideo.com/videoStatus.jsp?contId={contId}"
resp = requests.get(vedioStatusUrl, headers=headers)
dic = resp.json()
print(dic)
srcUrl = dic['videoInfo']['videos']['srcUrl'] -> 从字典中取出srcUrl
systemTime = dic['systemTime']
srcUrl = srcUrl.replace(systemTime,f"cont-{contId}")
print(srcUrl) -> https://video.pearvideo.com/mp4/adshort/20210610/cont-1731815-15692888_adpkg-ad_hd.mp4
# 下载视频
with open("a.mp4", mode="wb") as f:
f.write(requests.get(srcUrl).content)
f.close()三、代理
原理:通过第三方的 IP 去发送请求
import requests
proxies = {
"https": "https://218.60.8.83:3129"
}
res = requests.get("https:www.baidu.com", proxies=proxies)
res.encoding = 'utf-8'
print(res.text)四、多线程
线程与进程的区别:
线程是执行单位
进程是资源单位,每一个进程至少需要一个线程
from threading import Thread
# 子线程
def func():
for i in range(1000):
print("func", i)
# 主线程
if __name__ == "__main__":
t = Thread(target=func) # 创建线程并给线程安排任务
t.start() # 多线程状态为可以开始工作状态(开启线程),具体执行时间由CPU决定
for i in range(1000):
print("main", i)
# 创建多线程
from multipleprocessing import Process
def func():
for i in range(1000):
print("子进程", i)
if __name__ == '__main__':
p = Process(target=func)
p.start()
for i in range(1000):
print("主进程", i)
五、线程池与进程池
线程池/进程池:一次性开辟一些线程/进程,向线程池/进程池提交任务,线程/进程任务的调度交给线程池/进程池来完成
from concurrent.futures import ThreadPoolExecutor, ProcessPoolExecutor
def fn(name):
for i in range(1000):
print(name, i)
if __name__ == '__main__':
# 创建线程池
with ThreadPoolExecutor(50) as t:
for i in range(100):
t.submit(fn, name=f"线程{i}")
print('over!')