
前瞻
昨天,在公司项目中使用写的 calculate-cn-node 脚本时,出现了一个内存超标的错误,于是晚上回去进行了优化,总结出了很多问题。
借着这个机会,也好好地梳理一下JavaScript Garbage Collection(GC)和V8 Engine垃圾回收机制。
以下是内存超标版本的源码:
const path = require("path");
const fs = require("fs");
const createCsvWriter = require("csv-writer").createObjectCsvWriter;
const Segment = require("segment");
const chineseRegex = /[\u4e00-\u9fa5]/g;
const matchCnStringLiteral = /'[\u4e00-\u9fa5]+'/g;
const commentRegex = /\/\/.*|\/\*[\s\S]*?\*\//g;
const consoleRegex = /console\..*/g;
const info = [];
function calculateCnNode(directory) {
const segment = new Segment();
segment.useDefault();
const files = fs.readdirSync(directory);
for (let i = 0; i < files.length; i++) {
const file = files[i];
const filePath = path.join(directory, file);
const stats = fs.statSync(filePath);
if (stats.isDirectory()) {
calculateCnNode(filePath);
} else if (stats.isFile()) {
const fileContent = fs.readFileSync(filePath, "utf-8");
const lines = fileContent.split(/\r?\n/);
for (let j = 0; j < lines.length; j++) {
const line = lines[j];
if (!commentRegex.test(line) && !consoleRegex.test(line)) {
const chineseMatches = line.match(chineseRegex);
if (chineseMatches) {
const chineseString = chineseMatches.join("");
const words = segment.doSegment(chineseString, {
simple: true,
stripPunctuation: true,
});
const wordIndex = line.indexOf(words);
info.push({
char: words,
line: j + 1,
column: wordIndex + 1,
file: filePath,
});
}
const stringLiteralMatches = line.match(matchCnStringLiteral);
if (stringLiteralMatches) {
for (const match of stringLiteralMatches) {
const chineseString = match.slice(1, -1);
const words = segment.doSegment(chineseString, {
simple: true,
stripPunctuation: true,
});
const wordIndex = line.indexOf(words);
info.push({
char: words,
line: j + 1,
column: wordIndex + 1,
file: filePath,
});
}
}
}
}
}
}
}
const input = process.argv[2];
const output = process.argv[3];
calculateCnNode(input);
const csvWriter = createCsvWriter({
path: output,
header: [
{ id: "char", title: "Character" },
{ id: "line", title: "Line" },
{ id: "column", title: "Column" },
{ id: "file", title: "File" },
],
});
csvWriter.writeRecords(info).then(() => {
console.log("CSV file written successfully");
});出错后,晚上回家分析了一下,发现了几点问题:
- Segment 对象被放在了函数中创建
- 在遇见大量数据或文件时,采用同步读取文件的方式会阻塞主线程,从而导致效率过低
- 所有的结果被写入到一个数组中,少量数据时数组可以支撑;在大量数据下,数组显然不是一个好的存储方式
- 指定遍历的文件夹下可能会存在大量的资源文件(如图片、样式、图标等等),读取这些文件会造成乱码与程序阻塞等问题
在发现上述问题后,对代码进行了优化,并一一对上述问题进行解决:
- Segment 对象移到全局中,只创建一次
- 采用异步或者流式的方式来读取文件
- 采用流式的方式将结果写入文件
- 避免遍历上述提到的资源文件
优化后的代码:
const path = require("path");
const fs = require("fs");
const createCsvWriter = require("csv-writer").createObjectCsvWriter;
const Segment = require("segment");
const chineseRegex = /[\u4e00-\u9fa5]/g;
const matchCnStringLiteral = /'[\u4e00-\u9fa5]+'/g;
const commentRegex = /\/\/.*|\/\*[\s\S]*?\*\//g;
const consoleRegex = /console\..*/g;
const segment = new Segment();
segment.useDefault();
/**
*
* @param {String} directory 需要遍历的文件夹
* @param {Object} csvWriter 创建的csvWriter对象
* @param {String} avoidFiles 需要避免遍历的文件
* @returns
*/
async function calculateCnNode(directory, csvWriter, avoidFiles) {
const baseName = path.basename(directory);
if (avoidFiles.includes(baseName)) return;
const files = await fs.promises.readdir(directory);
for (let i = 0; i < files.length; i++) {
const file = files[i];
const filePath = path.join(directory, file);
const stats = await fs.promises.stat(filePath);
if (stats.isDirectory()) {
await calculateCnNode(filePath, csvWriter, avoidFiles);
} else if (stats.isFile()) {
const fileContent = await fs.promises.readFile(filePath, "utf-8");
const lines = fileContent.split(/\r?\n/);
for (let j = 0; j < lines.length; j++) {
const line = lines[j];
if (!commentRegex.test(line) && !consoleRegex.test(line)) {
const chineseMatches = line.match(chineseRegex);
if (chineseMatches) {
const chineseString = chineseMatches.join("");
const words = segment.doSegment(chineseString, {
simple: true,
stripPunctuation: true,
});
const wordIndex = line.indexOf(words);
await csvWriter.writeRecords([
{
char: words,
line: j + 1,
column: wordIndex + 1,
file: filePath,
},
]);
}
const stringLiteralMatches = line.match(matchCnStringLiteral);
if (stringLiteralMatches) {
for (const match of stringLiteralMatches) {
const chineseString = match.slice(1, -1);
const words = segment.doSegment(chineseString, {
simple: true,
stripPunctuation: true,
});
const wordIndex = line.indexOf(words);
await csvWriter.writeRecords([
{
char: words,
line: j + 1,
column: wordIndex + 1,
file: filePath,
},
]);
}
}
}
}
}
console.log("当前已完成一个分词操作~");
}
}
const input = process.argv[2];
const output = process.argv[3];
const avoidArray = process.argv.slice(4);
const csvWriter = createCsvWriter({
path: output,
header: [
{ id: "char", title: "Character" },
{ id: "line", title: "Line" },
{ id: "column", title: "Column" },
{ id: "file", title: "File" },
],
});
csvWriter.writeRecords([]).then(() => {
calculateCnNode(input, csvWriter, avoidArray).then(() => {
console.log("CSV file written successfully");
});
});其实,关于避免遍历的文件可以扩展的更多,取决于项目以及你的需要。
回到出现问题的关键,在于内存。
当我们创建一个变量或者一个对象时,都会在内存中开辟一个空间去存储这些被创建的变量。但这个空间并不是无限大,特别是栈空间,在 V8 中栈空间的大小是被限制了的,具体可以去看之前的 V8 文章。不是无限大,就意味着如果我们没有及时清除那些没有使用的变量,那么当之后再创建新的变量时,就没有足够的空间去容纳,这就会导致内存超标。
Node 的内存超标问题可以将 Node 的内存限制直接调大,避免达到内存上限。但我觉得这只是一种临时解决方案,并不能一劳永逸或者说从根本上解决问题。
V8 垃圾回收机制
实际上,JavaScript Garbage Collection 的一切工作都是交给 V8 的垃圾回收机制来处理的。
在 V8 中存在着两个垃圾回收器,存在两个是因为这样能针对于不同的场景来更高效地回收垃圾。
垃圾数据是如何产生的
频繁地使用数据时,这些数据都会被放到栈和堆中。
常用的方式是,在内存中开辟一块空间,使用这块空间,在不需要的时候回收这块空间。
之前的文章提到过,栈空间一般存储的是函数调用,而堆空间一般存储的则是对象。
window.licodeao = new Object();
window.licodeao.a = new Uint16Array(100);例如,执行上述代码时,会先在 window 对象上创建一个 licodeao 属性,并在堆空间中创建一个空对象,将该空对象的地址指向了 window.licodeao 属性。随后又创建了一个空间大小为 100 的数组,并将地址指向了 licodeao.a 的属性值。
此时的内存布局:
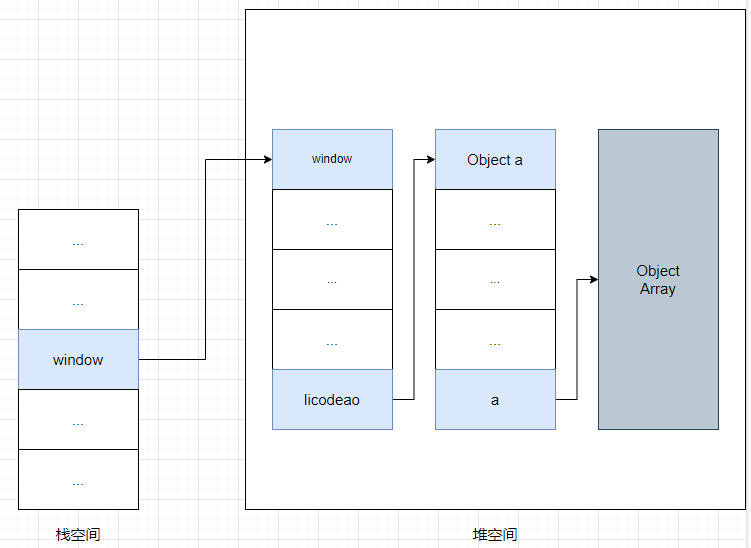
栈中保存了 window 的指针,可以通过该指针访问到 window 对象,通过 window 对象可以访问到 licodeao 对象,通过 licodeao 对象可以访问到 a 对象(数组也是对象嘛~)
如果将之前的代码更改成:
window.licodeao.a = new Object();那么此时 a 对象就不会指向之前的数组对象了,而是会指向了一个空对象,那么此时堆中的数组对象就变成了垃圾数据,因为无法从一个根对象遍历到这个数组对象了。此时,V8 的垃圾回收器就起作用了。
垃圾回收算法
垃圾回收的过程大致分为以下几步:
-
通过 GC Root 标记空间中的活动对象和非活动对象
V8 是如何判断一个对象是否是活动对象还是非活动对象的呢?
V8 采用的是可访问性算法(reachability)来判断堆中的对象是否是活动对象
可访问性算法具体是如何执行的呢?
其实就是以 GC Root 对象为起点,遍历 GC Root 中所有的对象
- 通过 GC Root 遍历到的对象,被认为是可访问的(reachable),既然可访问到,那么必须保证这些对象应该在内存中保留。可访问的对象也称为活动对象。
- 通过 GC Root 遍历不到的对象,被认为是不可访问的(unreachable),那么这些不能访问的对象就有可能被回收。不可访问的对象也称为非活动对象。
-
回收非活动对象占据的内存
- 在所有的标记完成后,统一地清理内存中所有被标记为可回收的对象
-
进行内存整理
- 在进行频繁地回收对象后,会造成内存中存在大量不连续空间,这些不连续的内存空间被称为内存碎片。
- 当内存中存在着大量的内存碎片,如果需要分配较大的连续内存时,可能会出现内存不足的情况。
- 因此,最后需要进行内存整理。但这一步骤不一定是必需的(可选),因为有的垃圾回收器(副垃圾回收器)不会产生内存碎片
垃圾回收器
前面提到,V8 目前采用两个垃圾回收器:
为什么会有两个垃圾回收器?
主要是受到了代际假说的影响,代际假说表明了很多对象在内存中存在的时间很短(die young)
代际假说有两个特点:
大部分对象在内存中的存在时间很短
如定义在函数或者块级作用域中的变量,当函数或者代码块执行结束时,作用域中的变量就会被销毁。
因此这一类对象一经分配内存,很快就会变得不可访问了
不死的对象,会活的很久
如全局的 window、DOM、Web API 等对象
V8 的垃圾回收策略就是基于该假说之上,如果只使用一个垃圾回收器,在优化大多数新对象时,很难优化到那些老对象,因此需要权衡各种场景,根据对象生命周期的不同,来使用不同的算法,以便达到最好的效果。因此,在 V8 中有两个垃圾回收器,并且把堆分为了新生代和老生代两个区域,新生代中存放的是生存时间短的对象,老生代中存放的是生存时间长的对象。
新生代通常只支持 1~8M的容量, 而老生代支持的容量就很多了,对于这两个区域,V8 分别使用了不同的垃圾回收器,以便高效地实现垃圾回收。
主垃圾回收器
主垃圾回收器(Major Garbage Collection)
-
主要负责老生代的垃圾回收
-
一些大的对象会直接被分配到老生代中,因此老生代中的对象有两个特点:
- 对象占用空间大
- 对象存活时间长
-
由于老生代中的对象比较大,若要在老生代中使用 Scavenger 算法进行垃圾回收,显然不是一个合适的办法,因为复制这些大的对象将会花费比较多的时间,从而导致回收执行效率不高,同时还会浪费一半的空间。因此,主垃圾回收器采用标记 - 清除(Mark - Sweep)算法来进行垃圾回收的。
标记 - 清除(Mark - Sweep)算法又是什么?
- 标记过程阶段:从一组根元素开始,递归遍历这组根元素,在这个遍历过程中,能到达的元素称为活动对象,没有到达的元素就可以判断为垃圾数据了。
- 垃圾清除阶段:它和副垃圾回收器的垃圾清除过程完全不同,主垃圾回收器会直接将被标记为垃圾的数据清理掉。
- 对垃圾数据进行标记,然后清除,这就是标记 - 清除算法。
-
对一块内存多次执行标记 - 清除算法后,会产生大量不连续的内存碎片,碎片如果过多,会导致大对象无法分配到足够的连续内存,于是又出现了另一种算法:标记 - 整理算法(Mark - Compact)
-
标记 - 整理算法(Mark -Compact)的标记过程仍然与标记 - 清除算法里的是一样的,先标记为可回收对象,但后续步骤就不是直接清除了,而是让所有存活的对象都向一端移动,然后直接清理掉这一端之外的内存。
副垃圾回收器
副垃圾回收器(Minor Garbage Collection)- Scavenger(又称为清道夫)
-
主要负责新生代的垃圾回收
-
新生代中的垃圾数据使用 Scavenger 算法来处理,所以副垃圾回收器又称为 Scavenger 清道夫
Scavenger 算法又是什么?
-
Scavenger 算法实际上就是将新生代空间分成了两块区域,一半是复制过来的对象区域(from-space),另一半是空闲区域(to-space)

-
新加入的对象就会被放入到对象区域(from-space),当对象区域快被写满时,此时就需要进行一次垃圾回收操作了。
-
在垃圾回收过程中,首先要对对象区域中的垃圾进行标记;标记完成后,就进入垃圾清理阶段了。副垃圾回收器会把这些存活的对象复制到空闲区域中,同时它还会把这些对象有序地排列起来,相当于完成了内存整理操作,复制后空闲区域就没有内存碎片了。
-
完成复制后,对象区域和空闲区域进行角色翻转,即原来的对象区域变成空闲区域,原来的空闲区域变成了对象区域,这样就完成了垃圾回收操作。这种角色翻转的操作还能让新生代中的两块区域无限重复使用下去。
-
副垃圾回收器每次执行清理操作时,都需要将存活的对象从对象区域复制到空闲区域,进行复制操作肯定需要时间成本,倘若新生代区域设置的太大,那么每次进行清理操作的时间就会很长,所以为了执行效率,一般新生代区域的空间会被设置得比较小。
-
正是因为新生代区域的空间不够大,所以很容易造成存活的对象装满整个区域,副垃圾回收器一旦监控到对象区域装满了,便会执行垃圾回收。同时,副垃圾回收器还采用了对象晋升策略,也就是移动那些经过两次垃圾回收依然还存活的对象到老生代区域中。
-
如何避免内存泄漏
尽管前端框架和浏览器已经帮助我们处理了常见的内存相关的问题,但是我们仍然有必要和义务去了解一些常见的内存泄漏问题以及龟波方式:
-
尽可能少地使用全局变量
全局变量因为其存在时间长并且会存储在老生代区域中,最终由主垃圾回收器进行回收。正因为其存在时间长,过多的全局变量会导致内存占用增加,即老生代区域中可使用空间减少。为了避免整个问题,应该减少全局变量的使用,尽可能将变量限定在局部作用域中。如果确实需要使用全局变量,确保在使用完毕后将其设置为
null,以便及时地进行垃圾回收和释放内存。 -
手动清除定时器
使用定时器时,一定要在适当的时机手动清除定时器。如果忘记清除定时器,定时器的回调函数将会一直执行,可能导致内存泄漏。确保在不需要定时器时,使用
clearTimeout和clearInterval主动清除定时器。 -
避免不必要的闭包
错误地使用闭包,可能会导致内存泄漏。当闭包中引用了外部函数的变量时,即使外部函数执行完毕,被引用的变量也不会被垃圾回收,直到闭包不再被引用。因此,避免创建不必要的闭包或确保在不需要的时候解除对闭包的引用,以便垃圾回收和释放内存。
function ClosureFn() { let data = "Data"; return function () { // 闭包中引用了外部函数的data变量 console.log(data); }; } let closure = ClosureFn(); // 当不再需要闭包时,解除对闭包的引用 closure = null; -
清除 DOM 引用
操作 DOM 元素时,确保在不需要使用它们时清除对 DOM 元素的引用。如果仍然保留对已经移除或隐藏的 DOM 元素的引用,这些被引用的 DOM 元素将无法被垃圾回收。
let el = document.getElementById("id"); // 手动清除引用 el = null; -
使用弱引用
WeakSet 和 WeakMap 可以帮助我们避免内存泄漏,这两个数据结构采用弱引用,当对象没有其他引用时,垃圾回收机制会自动释放它们所占用的内存。那么,引入这个新的数据结构带来了什么好处呢?使用
WeakSet和WeakMap可以减少手动清除引用的工作量。